
Difyは、ノーコード・ローコードで高度なAIアプリケーションを開発できる画期的なプラットフォームです。その魅力の核心にあるのが、AIの動作を部品のように組み合わせていく「ノード」という概念です。しかし、「種類が多くてどのノードをどう使えば良いかわからない」と感じる方も少なくないでしょう。
この記事では、Difyの心臓部ともいえる主要なノード、特に「LLMノード」「質問分類ノード」「パラメータ抽出ノード」「イテレーションノード」の4つに焦点を当て、その機能と効果的な使い方を徹底的に解説します。この記事を読めば、各ノードの役割を正確に理解し、あなたのアイデアを形にするための具体的なワークフローを構築できるようになります。
Difyのノードとは?AIアプリ開発の基本を理解しよう
ノードの役割とワークフローの仕組み
Difyにおけるノードとは、AIアプリケーションの具体的な動作を定義する「機能部品」のようなものです。例えば、「ユーザーからの入力を受け取る」「大規模言語モデル(LLM)に指示を出す」「特定の条件で処理を分ける」といった一つひとつの機能が、個別のノードとして提供されています。
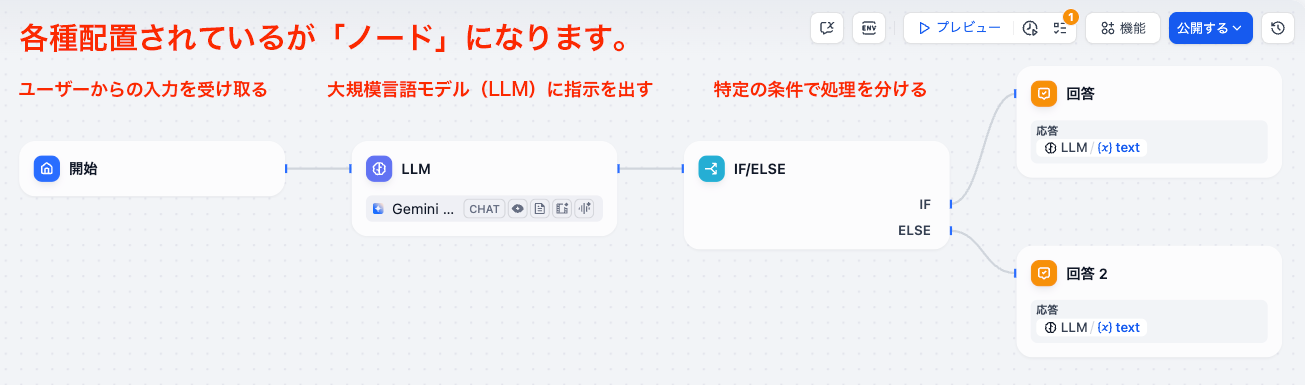
開発者はこれらのノードをキャンバス上に配置し、線でつなぎ合わせていくことで、データがどのように流れ、処理され、最終的に出力されるかという一連のプロセス、すなわち「ワークフロー」を構築します。この直感的な操作により、プログラミング経験が少ない方でも複雑なAIのロジックを視覚的に組み立てることが可能です。
ノードの種類とそれぞれの概要
Difyには、単純なテキスト処理から外部サービスとの連携まで、多岐にわたる機能を持つノードが用意されています。基本的なものには、プロセスの開始と終了を示す「開始ノード」や「終了ノード」、ユーザーに回答を返す「回答ノード」などがあります。
本記事では、その中でも特にAIアプリケーション開発の中核を担う、以下の4つの高度なノードについて詳しく解説します。

- LLMノード: AIの思考そのものを司る、プロンプト実行の心臓部
- 質問分類ノード: ユーザーの入力の意図を汲み取り、処理を分岐させる
- パラメータ抽出ノード: テキストから必要な情報だけを抜き出す
- イテレーションノード: 繰り返し処理を自動化し、作業を効率化する
これらのノードを使いこなすことが、Difyで高機能なAIアプリを開発するための鍵となります。
AIの頭脳を司る「LLMノード」の使い方
LLMノードの基本機能
LLMノードは、DifyのワークフローにおいてAIの頭脳として機能する、最も重要なノードの一つです。このノードを通じて、OpenAIのGPTシリーズやGoogleのGeminiといった、様々な大規模言語モデル(LLM)のAPIを呼び出すことができます。
主な用途は、プロンプト(指示文)に基づいてテキストを生成したり、入力された内容を要約・分析・翻訳したりすることです。
例えば、ユーザーからの質問に対して自然な回答を生成するチャットボットや、長い文章から要点を抽出するツールなど、AIの核となる処理のほとんどをこのLLMノードが担います。モデルの選択もノード内で簡単に行えるため、タスクに応じた最適なLLMを手軽に切り替えられる点も魅力です。
プロンプト設定の3つの要素:SYSTEM, USER, ASSISTANT
LLMノードの性能を最大限に引き出す鍵は、精度の高いプロンプトを作成することにあります。Difyでは、プロンプトを「SYSTEM」「USER」「ASSISTANT」の3つの役割に分けて設定することで、よりきめ細やかな制御を可能にしています。
| 項目 | 役割 | 具体例 |
|---|---|---|
| SYSTEM | AIアシスタントの全体的な振る舞いや役割を定義する(キャラクター設定) | 「あなたは親切で丁寧な日本語教師です。初心者にも分かりやすく説明してください。」 |
| USER | AIへの具体的な質問やリクエストを記述する | 「『は』と『が』の違いを教えてください。」 |
| ASSISTANT | AIの応答形式や模範解答の例を示す(Few-shotプロンプティング) | 「回答の雛形は以下でお願いします。 ・短く簡潔に違いを明記 ・比較表で明記 ・活用の一言アドバイス」 といった回答の雛形を示す。 |

このように役割を明確に分けることで、AIは自身の立場や求められているタスクを正確に理解し、一貫性のある高品質な応答を生成しやすくなります。
コンテキストとメモリの活用方法
LLMノードには、プロンプト以外にも重要な設定項目があります。その一つが「コンテキスト」です。ここには、ナレッジ検索ノードなどで取得したドキュメントやデータといった、比較的大きな情報ブロックを変数として渡します。これにより、LLMは外部の専門知識を参照しながら回答を生成できるようになり、より正確で詳細な応答が可能になります。
 コンテキストは「カンペ」、メモリは「会話履歴」をAIに渡すイメージで活用する
コンテキストは「カンペ」、メモリは「会話履歴」をAIに渡すイメージで活用するもう一つは「メモリ」機能です。これはチャット形式のアプリケーションでのみ利用可能で、過去の対話履歴を記憶させる役割を持ちます。ウィンドウサイズを設定することで記憶する会話のターン数を調整でき、文脈に沿った自然な会話を実現します。
ユーザーの意図を汲み取る「質問分類ノード」
質問分類ノードとは?条件分岐ノードとの違い
質問分類ノードは、ユーザーからの入力が、事前に定義した複数のカテゴリ(クラス)のうちどれに最も近いかをLLMが判断し、その後の処理フローを分岐させるためのノードです。
例えば、問い合わせ内容を「製品の操作に関する問題」「アフターサービスに関する問題」「その他の問題」の3つに自動で分類し、それぞれ専門の担当部署や情報ソースにつなぐといった使い方が可能です。
このノードは、単純な真偽(Yes/No)で分岐する条件分岐ノードとは異なり、文章のニュアンスといった曖昧な内容を扱えるのが最大の特徴です。
| ノード種類 | 分岐の基準 | 具体例 |
|---|---|---|
| 条件分岐ノード | 変数の値が特定条件を満たすか(真偽) | 「今日の天気は晴れ?」という質問に対し、YESかNOで分岐する。 |
| 質問分類ノード | 入力内容がどの分類に属するか(意味的な分類) | 「店員さんの接客がすごく良かった」という感想に対し、「ポジティブ」か「ネガティブ」かを判断して分岐する。 |
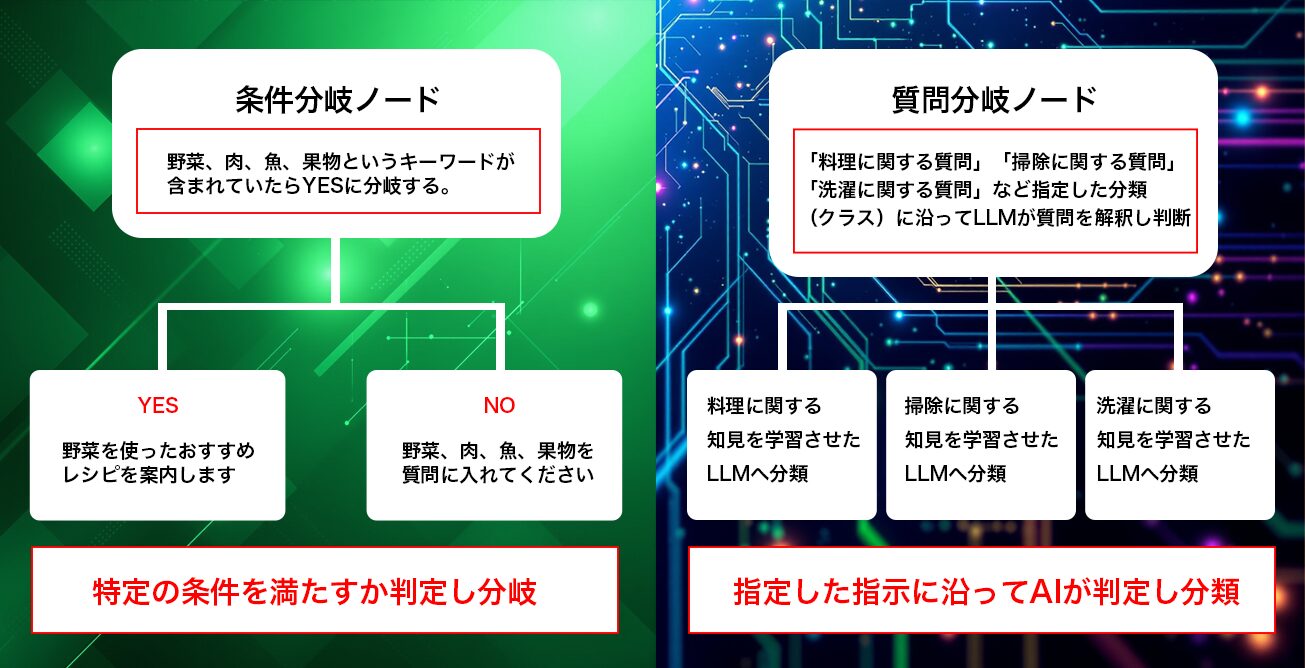
例えば、上記の画像で示している例では、条件分岐ノードを「ユーザーの質問に特定のキーワードが含まれているか」という明確な条件で処理をYES/NOに分岐させるために使っています。
一方、質問分類ノードは、「ユーザーの質問内容をAIが解釈し、あらかじめ設定した分類(クラス)に沿って、各分野の専門知識を学習させたLLMに処理を引き渡す」という使い方をしています。
このように、「条件分岐」は明確なルールに基づく機械的な判断、「質問分類」はAIによる意味の解釈に基づく柔軟な判断で処理を分岐させる、と整理すると分かりやすいでしょう。ユーザーの自由な入力に対して柔軟に対応できるため、より高度な対話システムの構築に役立ちます。
効果的な分類を実現する「クラス」設定のコツ
質問分類ノードの精度は、「クラス」の設定方法に大きく左右されます。クラスとは、分類先のカテゴリとその条件を定義するものです。ここで曖昧な条件や内容が重複するクラスを設定してしまうと、LLMが正しく分類できなくなる可能性があります。
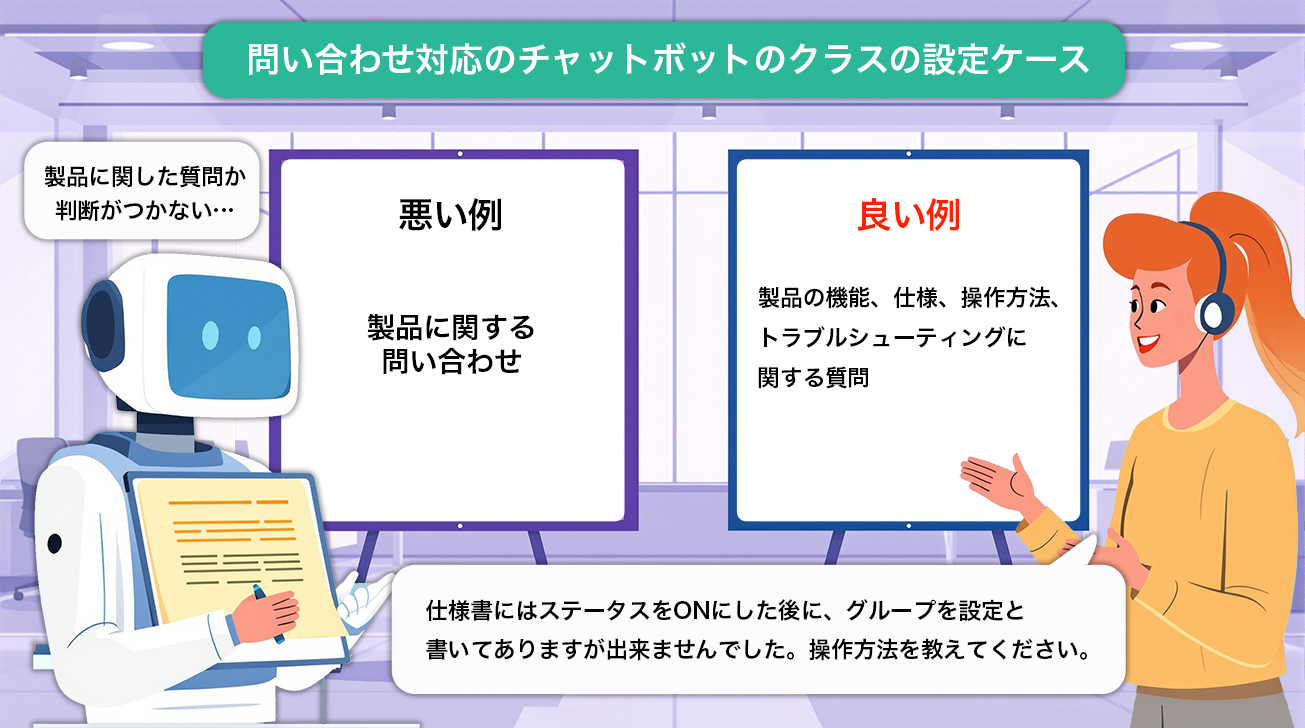
例えば、「製品に関する問い合わせ」というクラスであれば、「製品の機能、仕様、操作方法、トラブルシューティングに関する質問」のように具体的に定義します。
さらに「高度な設定」項目では、プロンプトのようにLLMへの指示を追加でき、より複雑な分類ルールを設けることも可能です。
テキストから情報を自動抽出「パラメータ抽出ノード」
パラメータ抽出ノードの役割
パラメータ抽出ノードは、ユーザーが入力した自然言語のテキストの中から、特定の意味を持つ情報(エンティティ)を構造化されたデータとして抽出するための強力なツールです。
例えば、「来週火曜日の午後3時に、東京駅で田中さんと打ち合わせ」というテキストから、「日時:来週火曜日の午後3時」「場所:東京駅」「人物:田中さん」といった情報をパラメーターとして自動で抜き出すことができます。
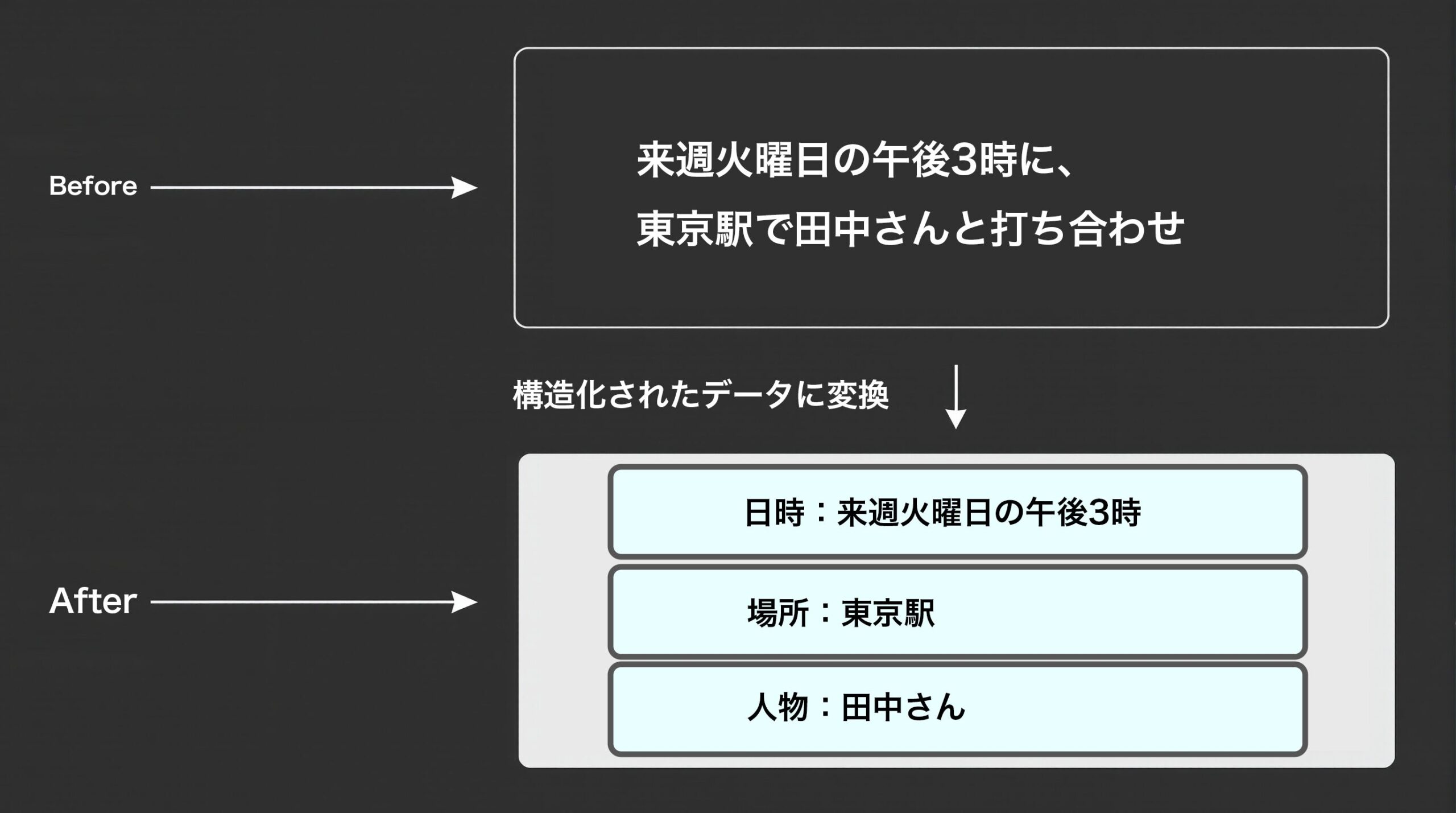
この機能により、非構造化テキストデータを後続のノードで扱いやすい形式に変換できます。抽出したパラメーターは、データベースへの登録、APIへのリクエスト送信、カレンダーへの予定登録など、様々な自動化処理に直接利用することができ、ワークフローの可能性を大きく広げます。
抽出精度を高める設定方法
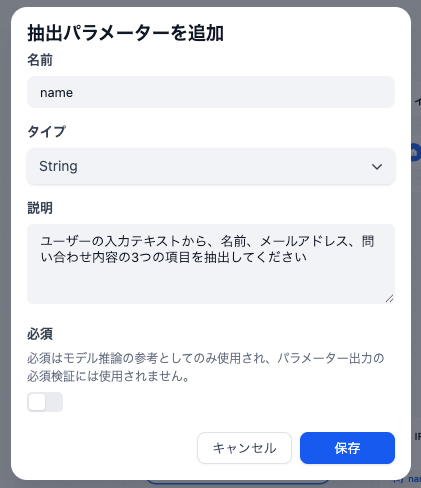
このノードの性能を最大限に引き出すには、抽出したいパラメーターの定義が重要です。まず、抽出する各パラメーターに対して「名前(例: name)」「タイプ(例: String, Number)」「説明(例: ユーザーの名前)」を正確に設定します。
特に重要なのが「指示(プロンプト)」の項目です。この欄を空欄にしても基本的な抽出は可能ですが、ここに「ユーザーの入力テキストから、名前、メールアドレス、問い合わせ内容の3つの項目を抽出してください」のように具体的な指示を記述することで、抽出の精度が大幅に向上します。使用するLLMのモデル性能も精度に影響するため、複雑な抽出を行いたい場合は、GPT-4oなどの高性能なモデルを選択することが推奨されます。
パラメータ抽出の注意点と対策
パラメータ抽出ノードを使用する上で、一つ注意すべき点があります。それは、各パラメーター設定にある「必須」というチェックボックスの挙動です。この「必須」設定は、LLMが抽出を試みる際の参考情報として使われるものであり、値が抽出できなかった場合に処理を停止させる厳密な入力チェック機能ではありません。
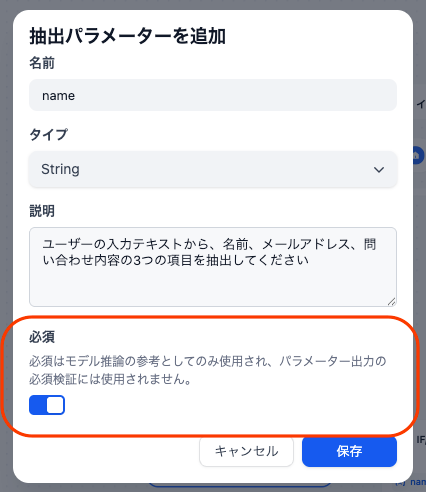
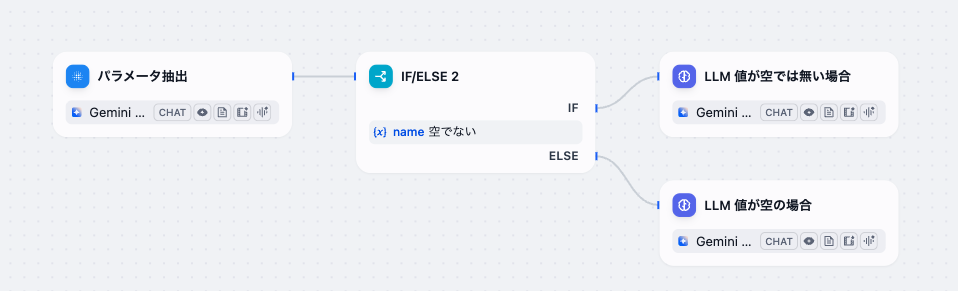
そのため、必須にチェックを入れていても、該当する情報がテキストに含まれていなければ、パラメーターが空のまま後続のノードに処理が渡ってしまうことがあります。これを防ぐためには、パラメータ抽出ノードの直後に「条件分岐ノード」を設置し、「抽出した変数が空でないこと」を判定するステップを追加することが有効な対策となります。
繰り返し処理を自動化する「イテレーションノード」
イテレーションノードの仕組みとメリット
イテレーションノードは、プログラミングにおける「ループ(繰り返し処理)」をノーコードで実現する非常に便利なノードです。例えば、CSVファイルに記載された100件の口コミデータ一つひとつに対して、「内容を分析し、改善案を生成する」といった同じ処理を適用したい場合に活躍します。
打ち合わせの予定をパタメータ抽出した時の、イテレーションノード活用時の処理イメージ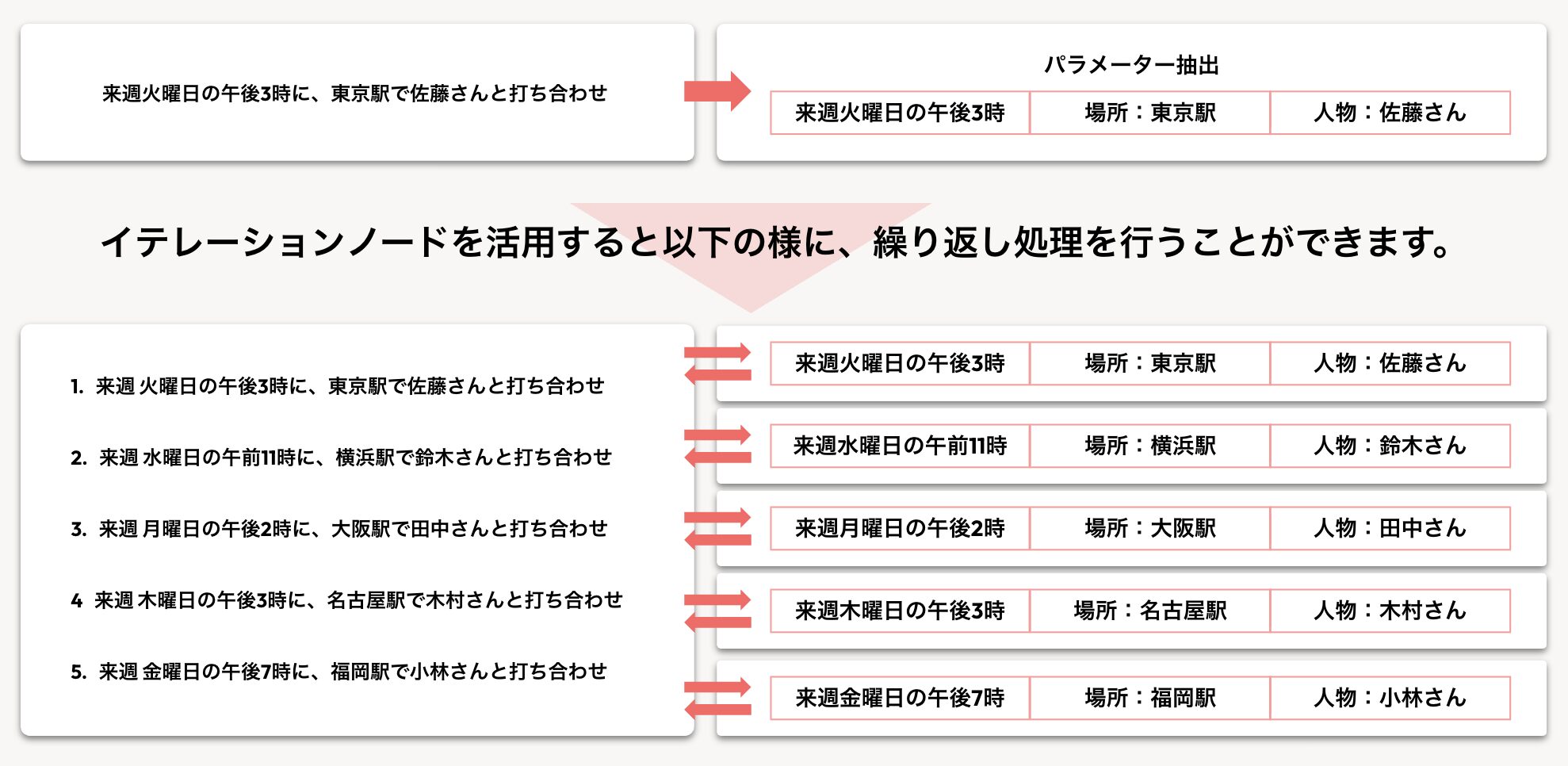
このノードを使わない場合、100回分の処理を手動で繰り返すか、複雑なワークフローを組む必要があります。しかし、イテレーションノードを使えば、一度処理内容を定義するだけで、指定したデータの数だけ自動で繰り返し実行してくれます。情報ソースでは「箱の中の5個のリンゴを1個ずつ取り出して磨く」作業に例えられており、大量のデータに対する定型作業を劇的に効率化できる点が最大のメリットです。
設定のポイント:入力と出力は「配列型」
イテレーションノードを正しく動作させるためには、一つ重要なルールがあります。それは、入力変数と出力変数が必ず「配列型(リスト形式)」のデータでなければならないという点です。単一のテキストや数値を入力として渡すことはできません。
設定の流れとしては、まず上流のノードで作成した配列型の変数をイテレーションノードの入力に設定します。次に、ノードの内部で、配列の各要素(例えば、口コミ1件分)に対して実行したい処理を、通常のワークフローと同じように他のノードを繋げて構築します。各要素の処理が完了すると、その結果が新しい配列に格納され、最終的にすべての処理結果がまとまった配列として出力されます。
高速化を実現する「パラレルモード」とは?
イテレーションノードには、「パラレルモード」というオプション機能が備わっています。これをONにすると、配列内の各要素に対する処理が、一つずつ順番に行われるのではなく、複数同時に並行して実行されるようになります。これにより、特に処理に時間のかかるLLMノードなどを内部に含む場合、全体の処理時間を大幅に短縮できる可能性があります。
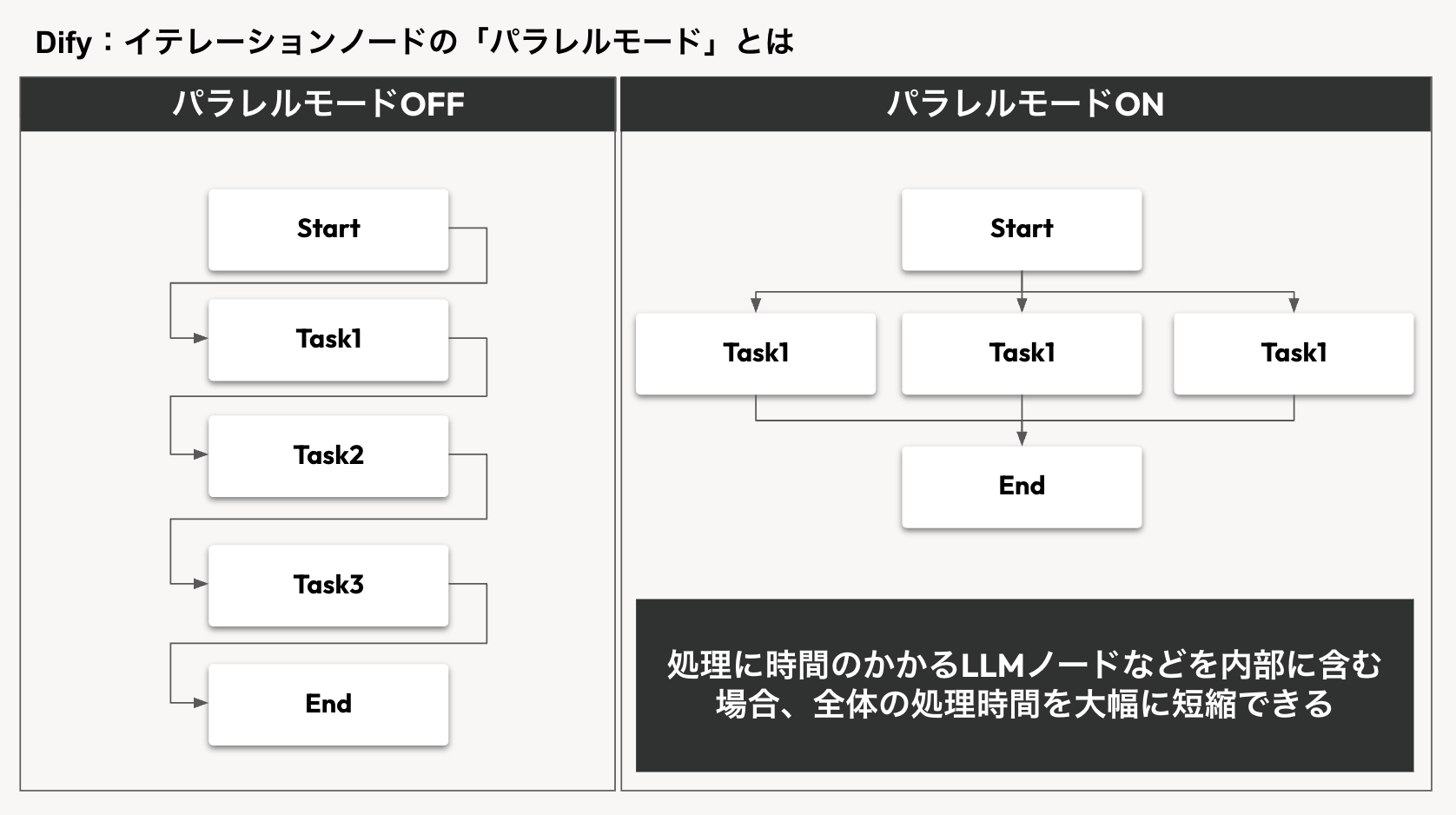
ただし、便利な機能である一方、注意点も存在します。パラレルモードでは処理の実行順序が保証されません。そのため、「前の処理結果を受けて次の処理を行いたい」といった、実行順が重要なワークフローには不向きです。処理速度と順序性のどちらを優先すべきか、タスクの性質に応じて使い分けることが重要です。
ご紹介した「LLMノード」「パラメータ抽出ノード」「イテレーションノード」を活用した高度なワークフローの事例について知りたい方は、以下のマーケティングリサーチの活用事例をご参考にしてください。
まとめ
本記事では、DifyにおけるAIアプリケーション開発の中核を担う4つの主要なノードについて、その機能と効果的な使い方を解説しました。
- LLMノード: AIの思考を司り、プロンプトを通じてテキスト生成や分析を行う。
- 質問分類ノード: ユーザーの意図を汲み取り、処理を柔軟に分岐させる。
- パラメータ抽出ノード: テキストから必要な情報を抜き出し、データとして活用する。
- イテレーションノード: 繰り返し処理を自動化し、大量のデータを効率的に扱う。
これらのノードは、それぞれが強力な機能を持ちながら、互いに組み合わせることで相乗効果を発揮します。Difyのノードを正しく理解し、自在に組み合わせることで、これまで専門的なプログラミング知識が必要だった複雑なタスクの自動化も実現可能です。ぜひ、この記事を参考にあなたのアイデアを形にする第一歩を踏み出してください。



